Version HTML de base


11
Le liage de sons successifs par le système auditif
Une autre expérience [8] a consisté à comparer les
difficultés relatives de la tâche présent/absent et de
la tâche up/down pour deux types de séquences sono-
res, où chaque fois un son pur (T) était suivi d’un ensem-
ble (E) de cinq sons purs espacés de 5,5 demi -tons.
Les éléments de E étaient soit synchrones (séquen-
ces du premier type), soit asynchrones (séquences du
second type). Dans le second cas, les éléments de E
se succédaient dans un ordre aléatoire, avec des écarts
temporels («stimulus onset asynchrony», SOA) de 100
ms ou 250 ms. Quelle que soit la séquence, l’intervalle
de temps séparant T du composant médian de E était
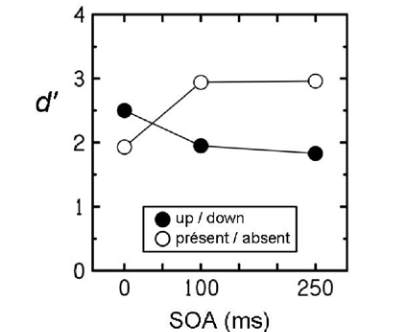
de 1 s. La figure 3 présente les performances moyennes
de cinq auditeurs. On voit que lorsque les éléments de
E étaient synchrones (SOA = 0), la tâche up/down a été
mieux réussie que la tâche présent/absent. Ce résultat
est cohérent avec ceux qui sont exposés dans la figure
2 (a). Notons cependant que l’avantage de la tâche up/
down a été moins prononcé dans la nouvelle expérience.
La raison en est probablement que, cette fois, T était
présenté non pas après l’accord mais avant lui : cela
permettait aux sujets de mieux percevoir individuelle-
ment un composant de l’accord identique à T.
Fig. 3 : Performances moyennes des sujets dans une
expérience de Demany, Semal, et Pressnitzer [8].
Mais le résultat le plus important de l’expérience est le
renversement de tendance obtenu lorsque les composants
de E sont devenus asynchrones : on voit dans la figure 3
que cette asynchronie a rendu la tâche présent/absent
plus facile que la tâche up/down. Cela invalide l’idée que
la tâche présent/absent est intrinsèquement difficile du
point de vue décisionnel. Subjectivement, une asynchro-
nie des composants de E rendait ces composants plus
faciles à percevoir individuellement. Telle est très proba-
blement l’origine du renversement de tendance.
Les propriétés des FSD
Un modèle qualitatif
On peut rendre compte des résultats paradoxaux décrits
ci-dessus à l’aide d’un modèle schématique de FSD qui
tient dans les trois hypothèses suivantes :
- Le système auditif contient deux sous-ensembles de
FSD, qui ont des préférences directionnelles opposées :
l’un répond préférentiellement à des augmentations de
fréquences, l’autre à des baisses.
- Chacun des deux sous-ensembles de FSD répond maxi-
malement à des
petits
changements de fréquence.
- Lorsqu’une séquence sonore active simultanément les
deux sous-ensembles de FSD, la direction perçue du chan-
gement est celle que préfère le sous-ensemble dont l’ac-
tivation est la plus forte.
Selon ce modèle, chaque fois que, dans nos expériences,
le son pur T devait être mis en relation avec un accord,
les deux sous-ensembles de FSD étaient activés simulta-
nément. Dans la condition up/down, cependant, chaque
séquence présentée au sujet devait (en vertu de l’hypo-
thèse 2) activer l’un des deux sous-ensembles plus forte-
ment que l’autre ; cette asymétrie indiquait au sujet la
réponse correcte. Dans la condition présent/absent, par
contre, chaque séquence devait selon le modèle activer
à peu près au même degré les deux sous-ensembles,
quelle que soit la réponse correcte ; les FSD fournis-
saient donc moins d’information utile, ce qui permet de
comprendre la faiblesse des performances enregistrées
dans cette condition. De meilleures performances étaient
prédites dans la condition présent/proche puisque cette
fois l’activation des FSD devait être symétrique quand la
réponse correcte était «présent» mais asymétrique dans
le cas contraire.
Nous supposons par ailleurs que les FSD sont activés
beaucoup plus fortement par deux sons purs immédia-
tement consécutifs (ou séparés par un silence) que par
deux sons purs entre lesquels vient s’interposer tempo-
rellement un troisième son pur. Cette supposition permet
de rendre compte de l’effet d’asynchronie dépeint dans
la figure 3. Elle est également justifiée par d’autres
données expérimentales [8]. Il apparaît cependant que
si, dans la tâche up/down, c’est un bruit large-bande
qui vient s’interposer entre un accord de sons purs et
le son pur T, ce bruit dégrade à peine la performance.
Nous l’avons constaté pour des bruits roses de même
sonie que les accords [8]. Ainsi, les FSD semblent insen-
sibles au bruit.
La taille optimale des changements de fréquence
Le modèle qualitatif exposé dans la section précédente
veut que les FSD répondent maximalement à des «petits»
changements de fréquence. Quelle est plus précisément
la taille des changements évoquant une réponse maxi -
male des FSD ? Nous l’avons estimée dans une étude [9]
où, une fois de plus, des auditeurs avaient à effectuer
la tâche up/down en réponse à des séquences sonores
constituées d’un accord de sons purs suivi d’un seul
son pur (T). Chaque accord était constitué de six sons
purs, espacés en fréquence de 650 «cents» (i.e., 6,5
demi -tons) pour certaines séquences et 1 000 cents
pour d’autres. Outre cet intervalle de fréquence (I ), nous
avons manipulé la durée des stimuli, la durée du silence
séparant l’accord de T, et surtout la taille de l’intervalle
de fréquence (
Δ,
en cents) séparant T du composant de
l’accord le plus proche en fréquence (celui -ci pouvait
être n’importe lequel des six composants). Notons que
Δ
était toujours largement inférieur à I/2, de sorte que
la tâche n’était jamais objectivement ambiguë.