Version HTML de base


22
Système de communication des perroquets gris du Gabon
Nos oiseaux ont ainsi produit certaines vocalisations plus
fréquemment dans certains contextes. Leur comportement
vocal répond ainsi à la première condition des signaux fonc-
tionnellement référentiels. Le fait que ces signaux puis-
sent véhiculer une information encodée par l’émetteur qui
puisse être intégrée par le récepteur reste cependant en
suspens. Des études supplémentaires sont ainsi néces-
saires pour valider cette hypothèse. Nous pouvons cepen-
dant mentionner les travaux conduits par Irène Pepperberg
et son perroquet gris Alex. Elle a montré, grâce à ses 30
années de recherche avec cet oiseau qu’il était capable
d’apprendre à imiter des mots humains et à les utiliser de
façon appropriée pour dénommer des objets, identifier des
différences entre des objets ou encore compter [1].
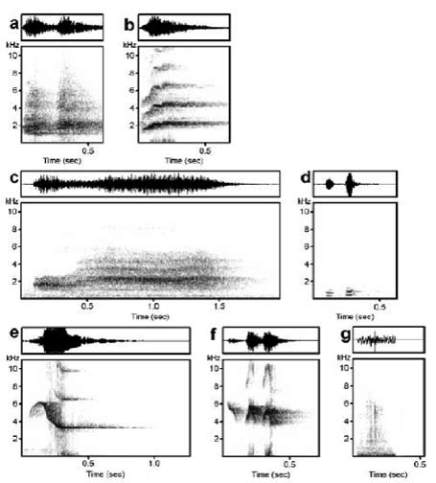
Fig. 2 : Vocalisations associées à un contexte
a : type C1; b: type C57; c: type C73; d: type C106; e: type
C77; f: type C85; g: type C112. Nos oiseaux ont produit le
cri de type C1 et C73 dans les contextes « proximité non
choisie face à un expérimentateur ou à un congénère»,
C73 dans le contexte « proximité non choisie face à un
congénère », C106 dans les contextes jouet et nourriture,
C57 dans le contexte présence d’un prédateur, C112 dans
le contexte soin et C77 et C85 dans le contexte sortie.
Fig. 2 : Vocalizations related to a context
a: C1 type; b: C57 type; c: C73 type; d: C106 type; e:
C77 type; f: C85 type; g: C112 type. Our birds produced
mainly “C1” and C73 calls in the “unwanted proximity
with an experimenter or a conspecific” contexts, “C106”
calls in the “toy” and “food” contexts, “C57” calls in the
“presence of an predator”, “C112” calls in the “care”
context and “C77” and “C85” calls in the “exit” context
Développement d’une méthode
d’analyse acoustique
Toutes les classifications des différentes vocalises, à partir
des séquences sonores enregistrées et de leurs analyses
acoustiques, ont été réalisées grâce à une écoute «experte».
Ce processus s’avère évidemment long et fastidieux. De ce
fait, nous avons par la suite cherché à mettre au point une
méthode d’analyse plus automatisée. Une étape essentielle
pour établir comment des informations peuvent être enco-
dées dans un signal (ex. : un cri de perroquet) qui intègrerait
un potentiel sens pour l’émetteur et/ou pour le récepteur est
d’identifier des spécificités acoustiques de ce signal.
Le chant des oiseaux est depuis plusieurs décennies au
centre de nombreuses recherches sur le comportement
animal et en particulier sur des paramètres acoustiques
susceptibles de traduire une information dans un chant
donnée [2]. Par exemple, des mâles de certaines espè-
ces d’oiseaux chanteurs, comme le canari domestique,
sont capables de produire des chants complexes, avec
des paramètres acoustiques précis, chants pour lesquels
des femelles manifestent leurs préférences. Comprendre
si et comment des caractéristiques objectives de vocali-
sations peuvent être liées à des caractéristiques objecti-
ves de leur contexte de production est ainsi une question
centrale du comportement des oiseaux. Cependant, cette
tâche, appliquée au cas des perroquets, s’avère délicate,
du fait de la grande diversité de leur répertoire. Une simpli-
fication de ce problème est donc nécessaire. Pour la mise
au point de notre méthode d’analyse, nous avons ainsi
choisi d’utiliser comme cible une catégorisation produite
par un humain expert et non par les contextes de produc-
tion de vocalisations. Cette méthode s’avère utile en tant
que telle pour les études en comportement animal si, par
la suite, elle permet d’interpréter de façon plus pertinente
la catégorisation humaine préalablement produite.
Nous avons donc cherché à développer une méthode
permettant de répondre à cet objectif. Pour cela, nous
avons sélectionné, parmi la base de données des vocalisa-
tions de perroquets enregistrées dans l’expérience précé-
dente, celles appartenant à cinq types de cri distincts et
étant spécifiques d’un stimulus donné : C 1, C 57, C 77,
C 106 et C 113. Cette sous-base de données, appelée
SBD, représentait 2 971 vocalisations. Nous avons alors
utilisé une approche de classification supervisée appelée
Extractor Discovery System (EDS), développée par Pachet
& Roy [3], approche qui permet de créer automatiquement
des modèles de classification audio spécifiques à partir
de fonctions pertinentes qui combinent elles mêmes des
opérateurs de traitement de signal. Cet espace de travail
en classification supervisée permet de réduire la charge de
travail en ne requérant qu’un petit échantillon de données
à classer par l’expérimentateur. Autrement dit, SBD a été
subdivisée en deux bases de données. La première, appe-
lée SBA (pour sous base d’apprentissage), contenait 100
exemplaires de chaque type de cri et a été utilisée pour
extraire des fonctions mathématiques de chaque signal
acoustique à l’aide d’EDS. EDS exploite une bibliothèque
d’opérateurs d’analyses acoustiques basiques comme
RMS (Root Mean Squared qui mesure l’énergie d’un signal),
ZCR (Zero-Crossing Rate qui mesure le nombre de fois
où un signal croise l’axe des x par seconde) ou encore la
Transformation Rapide de Fourier.
Ces opérateurs sont composés grâce à un algo-
rithme évolutif qui produit des fonctions mathémati -
ques complexes et arbitraires de traitement de signal.
L’espace de travail exploré par EDS est virtuellement
infini, mais une identification rapide de fonctions mathé-
matiques répondant au problème est réalisée grâce
à l ’exploitation d’un certain nombre d’heuristiques.